Durante del evento ASLAN 2025, nuestro compañero Víctor Rodríguez, especialista en virtualización, alta disponibilidad y formador oficial Proxmox, ha ofrecido una charla técnica centrada en la importancia de contar con un Disaster Recovery Plan (DRP) eficaz utilizando tecnologías open source como Proxmox VE, Ceph y Proxmox Backup Server. Durante su intervención, Víctor abordó múltiples escenarios reales que pueden afectar a la continuidad de los servicios TI y cómo anticiparse a ellos con herramientas bien configuradas y una estrategia de recuperación sólida.
A continuación, repasamos los puntos clave tratados en su presentación.

¿Qué es un DRP y por qué es imprescindible?
Si llevas un tiempo administrando sistemas y redes, probablemente hayas vivido algún evento desafortunado:
- Errores humanos.
- Fallos de hardware en momentos críticos.
- Averías en infraestructura.
- Incidentes de ciberseguridad.
Precisamente por eso, disponer de un Disaster Recovery Plan (DRP) es fundamental. Este plan nos ayuda a anticipar problemas, definiendo acciones claras para prevenir o responder ante incidentes.
Podemos verlo como una póliza de seguros: invertimos recursos esperando no tener que usarlos jamás. Pero atención, un desastre no necesariamente debe ser masivo: algo tan simple como borrar accidentalmente un fichero en una VM puede convertirse en un desastre si no tenemos un backup adecuado.
Siempre hay una primera vez, hasta para eso totalmente improbable que nunca le ha pasado a nadie y nos produce un destrozo…es literalmente imposible prever absolutamente todo, particularmente en lo relacionado con el factor humano y con la ciberseguridad.
Al hablar de DRP, debemos tener claros varios términos fundamentales:
- Recovery Point Objective (RPO): que es la cantidad de datos que podríamos llegar a perder, medida en tiempo.
- Recovery Time Objective (RTO): que es la cantidad de tiempo que podremos tener el sistema parado mientras recuperamos el sistema.
- Working Recovery Time (WRT): Tiempo necesario para verificar que lo recuperado funciona correctamente.
- Maximum Tolerable Downtime (MTD): Suma del RTO y WRT
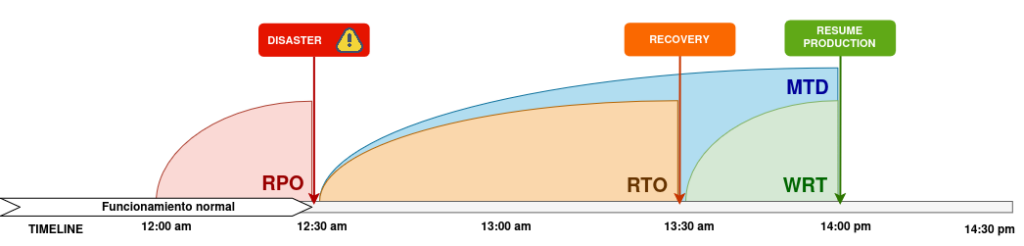
Los valores objetivo de cada uno de estos tiempos depende de las necesidades de negocio y la capacidad de inversión en el DRP: cuanto más acerquemos estos valores a 0, más recursos tendremos que invertir para conseguir ese objetivo.
DRP con Proxmox VE: la solución ideal
¿Qué es Proxmox VE, PBS y Ceph?
Por si alguien aún no está familiarizado con ellas, a continuación hago una breve introducción a las herramientas clave que utilizaremos para implementar nuestro plan de recuperación ante desastres (DRP):
- Proxmox VE (PVE): Plataforma open-source de virtualización que permite gestionar máquinas virtuales (VM) y contenedores LXC. Incorpora multitud de características útiles para implementar un DRP.
- Proxmox Backup Server (PBS): Sistema integrado de backups eficiente, deduplicado y seguro. Es la solución de copias de seguridad de Proxmox, totalmente integrada en PVE.
- Ceph: es el almacenamiento distribuido y redundante que proporciona la hiperconvergencia a un cluster PVE, sin puntos únicos de fallo.
Escenarios típicos y soluciones
A continuación, vamos a presentar una serie de situaciones que pueden surgir en cualquier entorno de sistemas, desde errores humanos, fallos críticos de infraestructura o incluso problemas de ciberseguridad. Veremos cómo podemos abordarlos de forma efectiva utilizando las herramientas que hemos mencionado.
1. Prevenir errores humanos
En muchas ocasiones, los errores no provienen de fallos técnicos sino de acciones humanas. Un caso típico es permitir que ciertos usuarios tengan permisos excesivos en Proxmox VE, lo que puede llevar a situaciones críticas como apagar o incluso borrar máquinas virtuales por accidente.
¿Qué opciones nos da Proxmox VE?
Proxmox VE ofrece un sistema de control de acceso muy granular, que permite definir con precisión quién puede hacer qué dentro de la plataforma. Además, es compatible con múltiples backends de autenticación y permite integrar doble factor (2FA), lo cual añade una capa adicional de seguridad a la gestión de permisos.
La solución es implementar un esquema de permisos adecuado, evitamos el «desastre».
De esta forma podemos esperar un RPO = 0 y un RTO= 0

¡Por favor, no le des permisos de root a todo el mundo!
2. Fallo de un switch
Uno de los switches que da conectividad a nuestro cluster Proxmox VE se avería, dejando a varios nodos sin acceso a red.
¿Qué opciones nos da Proxmox VE?
Proxmox VE soporta diversos modos de agregación de enlaces, incluido LACP 802.3ad, para otorgar redundancia y ampliar la capacidad en el acceso a la red. Con switches adecuados y configuraciones correctas (stack o MLAG), evitamos que la caída de un switch afecte al servicio.
Con la configuración adecuada obtendremos un RPO = 0 y RTO = 0
No tiene sentido diseñar un cluster con múltiples nodos, redundancia, etc. si no le damos la misma importancia a la red: es necesario utilizar switches redundantes en stack o MLAG y dar acceso a nuestros servidores de Proxmox VE al menos a dos switches.
3. Rotura de un disco del host
Uno de los discos de un servidor deja de funcionar, comprometiendo el almacenamiento local.
¿Qué opciones nos da Proxmox VE?
Proxmox VE permite redundancia sin necesidad de controladoras RAID. Podemos usar ZFS con mirror o RAIDz, o bien Ceph para distribuir y replicar los datos entre varios nodos del cluster.
La solución pasa por utilizar ZFS para instalar el sistema operativo y también para alojar nuestras máquinas virtuales. Sin embargo, siempre que sea posible se recomienda usar Ceph, ya que permite distribuir los datos de las VMs entre al menos tres discos ubicados en tres hosts distintos del cluster.
En ambos casos, se consigue una alta disponibilidad del almacenamiento, logrando así un RTO= 0 y RPO = 0
- ¡Usa mirror para los discos donde instales Proxmox VE!
- Utiliza Ceph para evitar el SPOF (Single Point of Failure) que supone utilizar una única cabina de almacenamiento
- Sí perdemos redundancia hasta que se reemplace el disco averiado: si el mirror es de 2 discos, ¡la rotura del segundo disco sí implica caída!
- Si tienes discos suficientes en el cluster, Ceph recupera automáticamente la redundancia.
4. Avería de un host
Un servidor se rompe o deja de responder.
¿Qué opciones nos da Proxmox VE?
En este caso contemplamos dos apartados diferentes:

Disponibilidad de los datos
Con ZFS, es posible configurar replicación periódica entre nodos del cluster, permitiendo la redundancia de los discos de las VMs. En cambio, Ceph mantiene la replicación de datos en tiempo real de forma distribuida entre múltiples nodos.
Disponibilidad de ejecución
En Proxmox VE disponemos de HA (alta disponibilidad). Aquellas VM que hayamos configurado en HA, el cluster se encargará de iniciarlas automáticamente en otro host en un tiempo de ~2 minutos.Usaremos Ceph siempre que sea posible para aprovechar su replicación en tiempo real. Si trabajamos con ZFS, configuraremos replicación periódica para las VMs que lo necesiten.
- Con ZFS
El RPO depende del intervalo de replicación y el RTO ronda los 2 minutos más el arranque de la VM.
- Con Ceph
El RPO es 0 y el RTO ronda los 2 minutos más el arranque de la VM.
- Sí, al caer el host las VM que ejecuta se detendrán repentinamente, por lo que es posible que el sistema de ficheros de la VM tenga que reparar algo y podría perderse algo de información.
- Como Proxmox VE es multimaster, todos los hosts tienen toda la configuración
- Se puede parametrizar en qué nodos queremos que se ejecuten, entre otras cosas.
5. Sufrimos un problema de ciberseguridad
Detectamos un ataque de ransomware que compromete la integridad de varias de nuestras máquinas virtuales, poniendo en riesgo tanto los datos como la continuidad del servicio.
¿Qué opciones nos da Proxmox VE?
QEMU dirty map para realizar backups frecuentes de nuestras máquinas virtuales, con una carga reducida en la infraestructura, de manera que podemos proteger mejor nuestras VM.
Si usamos Ceph, tenemos un botón que va a permitir poner en «pausa» todo nuestro almacenamiento, limitando así el desastre.
Mediante API podemos integrar herramientas SIEM para realizar acciones automáticamente ante ciertos eventos: apagar VMs, pausar Ceph, levantar reglas del firewall integrado de Proxmox VE…
Es factible implementar snapshots automáticos para reducir el RPO y RTO.
Solución aplicada:
- Haremos backups frecuentes de nuestras VM.
- Usaremos herramientas SIEM para monitorizar qué ocurre en las VM.
- Capacidad de reacción ante estos eventos (y siempre nos queda «tirar del cable»).
- Planifica tener backup fuera de tu infraestructura principal/offline.
El RPO y RTO dependerán de la estrategia utilizada: con snapshots son muy bajos (pudiendo rondar 1 minuto), mientras que solo con backups varían más y suelen ser medios o altos, según la frecuencia de las copias, el hardware y la red disponible.
6. Tolerancia a nivel de CPD con PBS
Queremos proporcionar redundancia a nivel de CPD y me puedo permitir RPO / RTO altos
¿Qué opciones nos da Proxmox PBS?
En un CPD alternativo, diferente al principal, usaremos un servidor PBS remoto con una réplica de los backups que realicemos en el PBS del CPD principal. Como podemos tener PVE y PBS en el mismo host, si lo dimensionamos correctamente podremos levantar ciertas máquinas virtuales en este host PBS. Esto nos puede servir para:
- Ejecutar las VM más importantes en el CPD alternativo en caso de desastre.
- Levantar VMs y realizar auditorías de seguridad en una red completamente aislada de la de Producción pero con conectividad entre las VM como si estuvieran en el cluster principal.
- Verificar periódicamente que efectivamente nuestro DRP funciona y podremos restaurar nuestras VMs y que las aplicaciones funcionarán correctamente.
La solución consiste en implementar una política de backups locales junto con réplica remota utilizando Proxmox Backup Server (PBS). Es fundamental verificar periódicamente que las copias funcionan correctamente realizando restauraciones en el PBS remoto. Además, se debe definir el DRP completo, incluyendo todos los pasos necesarios para poner en marcha las VMs y aplicaciones en el centro de datos alternativo.
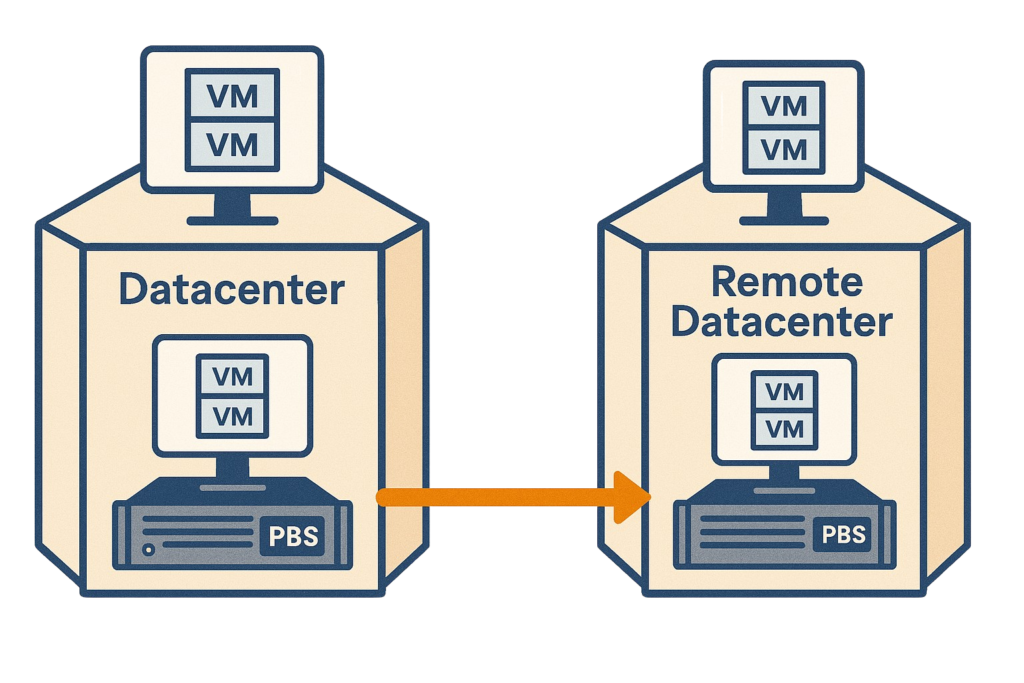
RTO:
Depende de la periodicidad de los backups y de la velocidad de sincronización entre el PBS principal y el PBS remoto.
RPO:
Depende del hardware y de la capacidad de la red, pero son tiempos medios / altos.
- Dimensiona tu PBS local y remoto según tus requisitos de RPO/RTO.
- Aloja tu PBS remoto en centros de datos confiables, que en caso necesario puedan proporcionarte servidores PVE de manera ágil para ejecutar más VMs.
- Podríamos tener conectividad en capa 2 entre los CPD mediante SDN integrado en PVE.
- Si se usa el CPD alternativo en caso de desastre quizás tengamos que modificar DNS, usar BGP o balanceadores en la nube para que nuestras aplicaciones sigan siendo alcanzables desde Internet.
7. Tolerancia a nivel de CPD con Ceph
Queremos proporcionar redundancia a nivel de CPD pero requiero un RPO/RTO lo más reducido posible.
¿Qué opciones nos da Ceph?
Se plantean dos posibilidades, ambas utilizando Ceph:
- Replica Ceph entre clusters PVE: podremos tener dos clusters PVE + Ceph en dos centros de datos separados, sin restricciones de distancia. Las escrituras que se realicen en las VM del CPD principal se replicarán hacia el CPD remoto. Se puede hacer en tiempo casi real o de manera periódica.
- Utilizando 3 centros de datos, dos con cluster PVE Ceph y un tercero que actúe de testigo, podríamos activar el modo Ceph Streched Cluster. Aquí todas las escrituras se realizan en tiempo “real” en los dos cluster PVE Ceph.
El RPO y RTO, dependen totalmente de las infraestructuras de red, de los requisitos de I/O de las VM, del hardware de almacenamiento, etcétera. Son opciones con requisitos estrictos para proporcionar un funcionamiento adecuado, siendo el modo Ceph Strech Cluster el mas exigente con diferencia.
Otras alternativas útiles
Alquilar servidores en OVH, de quienes somos integrador de referencia para productos Proxmox.
Incluso disponen de regiones 3AZ con 3 centros de datos a distancias adecuadas para tener un cluster distribuido geográficamente.

Tolerancia a nivel de aplicación: hay casos en los que resulta mas conveniente otorgar la alta disponibilidad a nivel de aplicación en vez de con infraestructura o combinando ambas opciones. Por ejemplo MySQL Galera Cluster, HAProxy, Keepalived, PostgreSQL + Patroni, etcétera.
Conclusión
Proxmox VE, PBS y Ceph conforman una solución sólida y flexible para implementar un DRP eficaz y adaptado a distintas necesidades empresariales.
¡Y todo esto es 100% Open Source y de código abierto!
Si deseas más información o asesoría personalizada, no dudes en escribirnos: info@soltecisis.com
