During the ASLAN 2025 event, our colleague Víctor Rodríguez, an expert in virtualization, high availability, and official Proxmox trainer, gave a technical talk focused on the importance of having an effective Disaster Recovery Plan (DRP) using open source technologies like Proxmox VE, Ceph, and Proxmox Backup Server. In his session, Víctor covered multiple real-world scenarios that can impact IT service continuity and how to stay ahead of them with well-configured tools and a solid recovery strategy.
Below, we go over the key points covered in his presentation.

What is a DRP and Why Is It Essential?
If you’ve been managing systems and networks for a while, you’ve probably experienced some unfortunate events:
- Human errors.
- Hardware failures at critical moments.
- Infrastructure breakdowns.
- Cybersecurity incidents.
That’s exactly why having a Disaster Recovery Plan (DRP) is essential. This plan helps us anticipate problems by defining clear actions to prevent or respond to incidents.
You can think of it like an insurance policy: we invest resources hoping never to need it. But beware — a disaster doesn’t have to be massive. Something as simple as accidentally deleting a file in a VM can turn into a disaster if we don’t have a proper backup.
There’s always a first time, even for those extremely unlikely things that “have never happened to anyone” and end up causing serious damage… It’s literally impossible to foresee absolutely everything, especially when it comes to human error or cybersecurity.
When talking about a DRP, there are several key terms we need to understand:
- Recovery Point Objective (RPO): the amount of data we could lose, measured in time.
- Recovery Time Objective (RTO): the amount of time the system can remain down while we recover it.
- Working Recovery Time (WRT): the time needed to verify that the recovered system works properly.
- Maximum Tolerable Downtime (MTD): the sum of RTO and WRT.
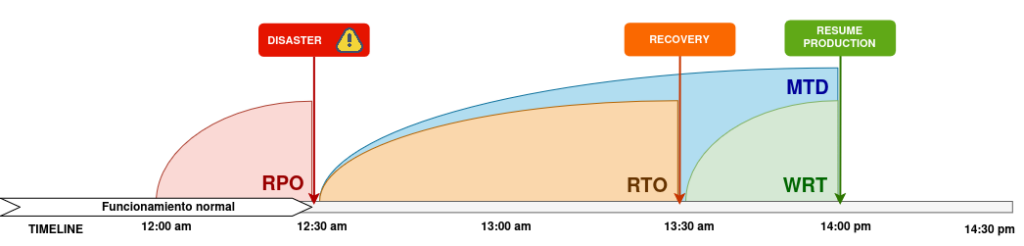
The target values for each of these times depend on business needs and the level of investment in the DRP: the closer we aim for these values to be 0, the more resources we’ll need to invest to achieve that goal.
DRP with Proxmox VE: The Ideal Solution
What Are Proxmox VE, PBS, and Ceph?
In case anyone is not yet familiar with them, here’s a brief introduction to the key tools we’ll use to implement our Disaster Recovery Plan (DRP):
- Proxmox VE (PVE): An open-source virtualization platform that allows you to manage virtual machines (VMs) and LXC containers. It includes many useful features for implementing a DRP.
- Proxmox Backup Server (PBS): An efficient, deduplicated, and secure integrated backup system. It’s Proxmox’s native backup solution, fully integrated with PVE.
- Ceph: A distributed and redundant storage system that brings hyperconvergence to a PVE cluster, with no single points of failure.
Typical Scenarios and Solutions
Next, we’ll present a series of situations that can arise in any IT environment — from human errors and critical infrastructure failures to cybersecurity issues. We’ll look at how to tackle them effectively using the tools we’ve just mentioned.
1. Preventing Human Errors
In many cases, incidents are not caused by technical failures but by human actions. A typical example is granting users excessive permissions in Proxmox VE, which can lead to critical situations such as accidentally shutting down or even deleting virtual machines.
What options does Proxmox VE offer?
Proxmox VE offers a very granular access control system, allowing you to precisely define who can do what within the platform. It also supports multiple authentication backends and allows for two-factor authentication (2FA), which adds an extra layer of security to permission management.
The solution is to implement a proper permissions scheme — that’s how we avoid “disaster.”
This way, we can aim for a RPO = 0 and RTO = 0

Please, don’t give root permissions to everyone!
2. Switch Failure
One of the switches providing connectivity to our Proxmox VE cluster fails, leaving several nodes without network access.
What options does Proxmox VE offer?
Proxmox VE supports various link aggregation modes, including LACP 802.3ad, to provide redundancy and increase network access capacity. With proper switches and correct configurations (stack or MLAG), we can prevent a switch failure from affecting the service.
With the right configuration, we can achieve a RPO = 0 and RTO = 0
There’s no point in designing a cluster with multiple nodes, redundancy, etc., if we don’t give the same importance to the network. It’s essential to use redundant switches in a stack or MLAG setup and connect our Proxmox VE servers to at least two switches.
3. Host Disk Failure
One of the disks in a server fails, compromising local storage.
What options does Proxmox VE offer?
Proxmox VE allows for redundancy without the need for RAID controllers. We can use ZFS with mirror or RAIDz, or Ceph to distribute and replicate data across multiple nodes in the cluster.
The solution is to use ZFS to install the operating system and also to host our virtual machines. However, whenever possible, it’s recommended to use Ceph, as it allows VM data to be distributed across at least three disks located on three different hosts in the cluster.
In both cases, high availability of storage is achieved, resulting in a RTO = 0 and RPO = 0
- Use a mirror for the disks where you install Proxmox VE!
- Use Ceph to avoid the SPOF (Single Point of Failure) that comes with using a single storage array.
- You do lose redundancy until the failed disk is replaced: if the mirror is made up of 2 disks, a second disk failure will cause downtime!
- If there are enough disks in the cluster, Ceph automatically restores redundancy.
4. Host Failure
A server breaks down or stops responding.
What options does Proxmox VE offer?
In this case, we consider two different aspects:

Data availability
With ZFS, it’s possible to set up periodic replication between cluster nodes, allowing VM disk redundancy. In contrast, Ceph maintains real-time data replication distributed across multiple nodes.
Execution availability
In Proxmox VE, we have HA (High Availability). For any VMs configured with HA, the cluster will automatically start them on another host within ~2 minutes. We’ll use Ceph whenever possible to take advantage of its real-time replication. If we’re working with ZFS, we’ll set up periodic replication for the VMs that require it.
- With ZFS
RPO depends on the replication interval and RTO is around 2 minutes plus the VM boot time.
- With Ceph
RPO is 0 and RTO is around 2 minutes, plus the VM boot time.
- Yes, if the host goes down, the VMs it was running will stop abruptly, so the VM’s file system might need repair and some data could be lost.
- Since Proxmox VE is multimaster, all hosts have the full configuration
- You can define on which nodes you want them to run, among other things.
5. We Experience a Cybersecurity Incident
We detect a ransomware attack compromising the integrity of several of our virtual machines, putting both data and service continuity at risk.
What Options Does Proxmox VE Offer?
QEMU Dirty Bitmap allows us to perform frequent backups of our virtual machines with minimal load on the infrastructure, providing better protection for our VMs.
If we are using Ceph, there is an option to “pause” the entire storage system, helping to contain the damage.
Through the API, we can integrate SIEM tools to automatically perform actions upon detecting certain events: shutting down VMs, pausing Ceph operations, activating firewall rules within Proxmox VE…
It is also possible to implement automatic snapshots to further reduce RPO and RTO.
- Perform frequent backups of our VMs.
- Use SIEM tools to monitor activity within the VMs.
- Ensure the ability to react quickly to these events (and, as a last resort, be ready to “pull the plug”).
- Plan to have backups stored outside your main infrastructure — offline backups are crucial.
RPO and RTO will depend on the strategy used: with snapshots, they’re very low (around 1 minute), while with backups only, they vary more and are usually medium or high—depending on the backup frequency, hardware, and available network.
6. Datacenter-Level Tolerance with PBS
We Want to Provide Datacenter-Level Redundancy and Can Tolerate High RPO/RTO
What options does Proxmox PBS offer?
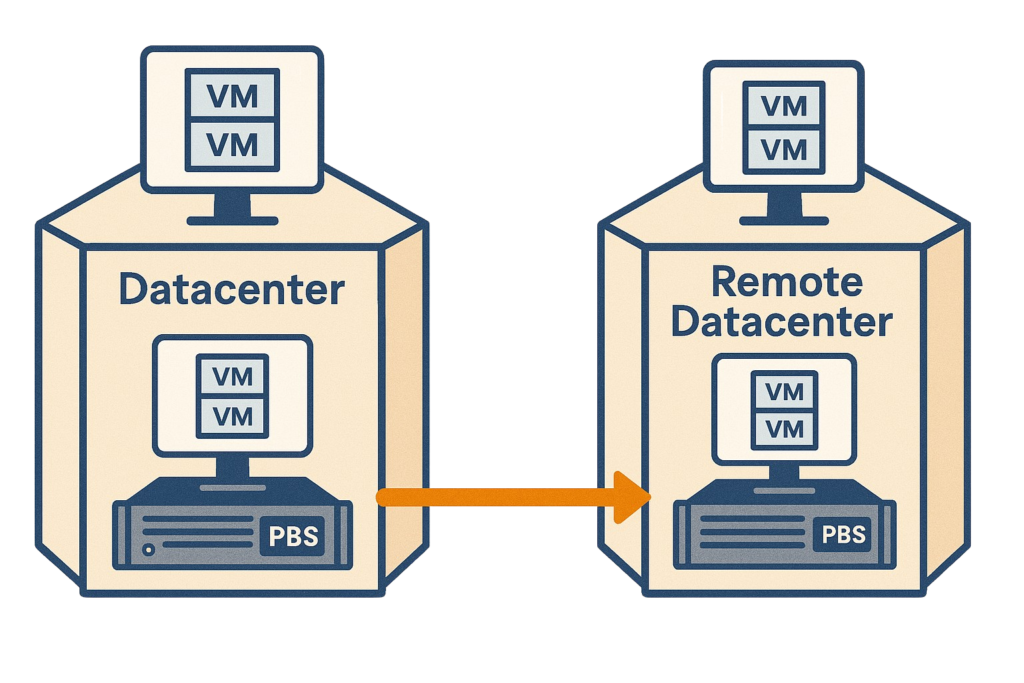
In a secondary data center, different from the main one, we use a remote PBS server with a replica of the backups made on the PBS in the main data center. Since we can have both PVE and PBS on the same host, if properly sized, we can run certain virtual machines on this PBS host. This can be useful for:
- Running the most important VMs in the alternate data center in case of disaster.
- Starting VMs and performing security audits in a network completely isolated from Production, but with connectivity between the VMs as if they were in the main cluster.
- Periodically verifying that our DRP actually works and that we can restore our VMs and their applications will function properly.
The solution is to implement a local backup policy along with remote replication using Proxmox Backup Server (PBS). It’s essential to regularly verify that the backups are working correctly by performing restores on the remote PBS. Additionally, the full DRP must be defined, including all the necessary steps to bring up the VMs and applications in the alternate data center.
RTO:
Depends on the backup frequency and the synchronization speed between the main PBS and the remote PBS.
RPO:
Depends on the hardware and network capacity, but the times are generally medium to high.
- Size your local and remote PBS according to your RPO/RTO requirements.
- Host your remote PBS in reliable data centers that, if needed, can quickly provide you with PVE servers to run more VMs.
- You could have Layer 2 connectivity between data centers using SDN integrated with PVE.
- If the alternate data center is used in the event of a disaster, you may need to update DNS, use BGP, or cloud load balancers to ensure your applications remain accessible from the Internet.
7. Datacenter-Level Tolerance with Ceph
We want to provide redundancy at the data center level, but we require the lowest possible RPO/RTO.
What options does Ceph offer?
There are two possible approaches, both using Ceph:
- Ceph replication between PVE clusters: we can have two PVE + Ceph clusters in separate data centers, with no distance limitations. Writes made on the VMs in the main data center are replicated to the remote data center. This can be done almost in real time or periodically.
- By using 3 data centers—two with a PVE Ceph cluster and a third acting as a witness—we can enable Ceph Stretched Cluster mode. In this setup, all writes are done in “real” time on both PVE Ceph clusters.
RPO and RTO fully depend on the network infrastructure, the I/O requirements of the VMs, the storage hardware, and so on. These are options with strict requirements to ensure proper operation, with Ceph Stretched Cluster mode being by far the most demanding.
Other Useful Alternatives
Renting servers from OVH, where we are a reference integrator for Proxmox products.
OVH even offers 3AZ regions with three datacenters located at optimal distances to set up a geographically distributed cluster.

Application-level tolerance: in some cases, it’s more convenient to provide high availability at the application level instead of relying solely on infrastructure—or by combining both approaches. For example, MySQL Galera Cluster, HAProxy, Keepalived, PostgreSQL + Patroni, etc.
Conclusion
Proxmox VE, PBS, and Ceph together form a solid and flexible solution for implementing an effective Disaster Recovery Plan (DRP) tailored to different business needs.
And the best part — it’s all 100% Open Source!
If you would like more information or personalized advice, feel free to contact us at: info@soltecsis.com
